Hierarchy in Vision Models
This page is a mini literature review, mostly for my own purposes, used for the BioCLIP work. I update this page as I have time and energy to read and write about new papers. If you feel that your work should be mentioned here, please email me.
Our ICLR reviews for BioCLIP included lots of missing work, which forms the basis for my literature review.
Unless otherwise noted, ImageNet always refers to the 1K class variant from the ILSVRC 2012 challenge.
In general, I find the literature on hierarchy in vision to have two main conclusions:
- Computer vision models naturally learn hierarchical structures
- Hierarchical objectives never outperform regular objectives.
But if you disagree, let me know!
Literature Review
This page is ordered chronologically rather than by separate categories.
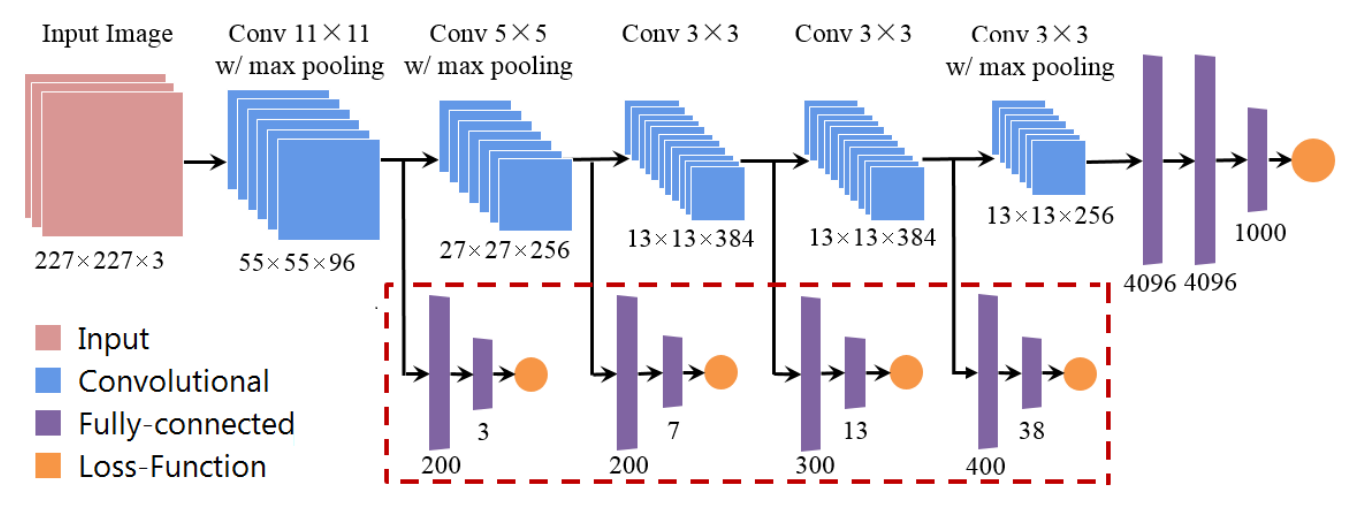
Bilal et al. 2017 (Do Convolutional Neural Networks Learn Class Hierarchy?, Block) develop a novel visual interface for analyzing CNN outputs on ImageNet. Honestly, they do a ton of important interpretability work and this paper is very full of insights. However, I am only interested in section 4.1.3, where they propose a new architecture to take advantage of the hierarchy present in ImageNet. Features from earlier layers branch into small fully-connected layers that predict coarser features. I assume the final loss is a sum of cross-entropy losses among all the levels in the hierarchy.
The authors find that this improved AlexNet leads to better top 1 error (42.6% to 34.3%). However, they note that this helps the issue of vanishing gradients because gradients for earlier layers are computed from the coarse-grained loss term. If the majority of the improvement comes from fixing vanishing gradients, then ResNets would not benefit from this multitask objective because they deal with vanishing gradients through the residual connections.
Taherkhani et al. 2019 (A Weakly Supervised Fine Label Classifier Enhanced by Coarse Supervision)
Bertinetto et al. 2020 (Making Better Mistakes: Leveraging Class Hierarchies with Deep Networks) propose measure mistake severity, wherein pedicting “dog” instead for the true label “cat” is a better mistake than predicting “jet plane”. They propose measuring mistake severity through tree distance in the hierarchical structure of ImageNet categories. While top-1 error decreased on ImageNet from 2012 to 2017 (and later), mistake severity did not. They propose two different training objectives, hierarchical cross entropy (HXE) and a soft (probability distribution) label on two hierarchical datasets, tieredImageNet and iNat19. They find that their hierarchy-aware training objectives lead to better mistake severity (lower tree distance when a prediction is wrong) but worse top-1 accuracy.
In general, I personally think this trade-off of top-1 accuracy vs better mistakes to be inescapable. Given that the computer vision community has optimized for top-1 accuracy (and specifically top-1 accuracy on ImageNet-1K), unless we can:
- Find one or more examples of where better mistakes, with lower top-1 accuracy, lead to better real-world outcomes.
- Set up a strong benchmark that is easy to evaluate and consistently correlates with real-world outcomes.
Then we will never care about “making better mistakes” over ImageNet top-1 accuracy. It’s simply too useful to throw away.
Elhamod et al. 2021 (Hierarchy-guided neural network for species classification, HGNN) train two ResNets, one to classify the genus, and one to classify the species. The species ResNet gets the features extracted from the genus ResNet added right before the final maxpool. Each image has a genus and a species label, and errors backpropogate through both networks. The models are pretrained on ImageNet. HGNN does better on the harder images (missing, occluded, etc.). This work partially motivates BioCLIP because we noted that biologists were using old models (ResNet) pretrained on general datsets (ImageNet) instead of strong, domain-specific vision models.
Cole et al. 2022 (On Label Granularity and Object Localization) compare the effects of label granularity on weakly supervised object location (WSOL). The goal of WSOL is to produce the bounding box for an object in an image where the image contains exactly one object and you know the class. That is, \(f(x, y) \rightarrow b\), where \(x \in \mathbb{R}^{h \times w \times 3}, y \in \mathcal{C}, b \in \mathbb{R}^{4}\). However, during training, you do not have lots of bounding boxes \(b\). Instead, the model must learn from a large set of \(x, y\) pairs and only a few \(x, y, b\) triplets. This work proposes a new WSOL dataset that is a subset of the iNat21 dataset, and shows that using coarser class labels (like order or class instead of species or genus) leads to stronger performance on the WSOL task.
Cole et al. 2022 (When Does Contrastive Visual Representation Learning Work?) investigate self-supervised pretraining beyond ImageNet. The most relevant section compares the differences between self-supervised pretraining on different granularities on both iNat21 and ImageNet. The authors find that SimCLR (their chosen self-supervised pretraining method) underperforms supervised methods on the finest-grained tasks.
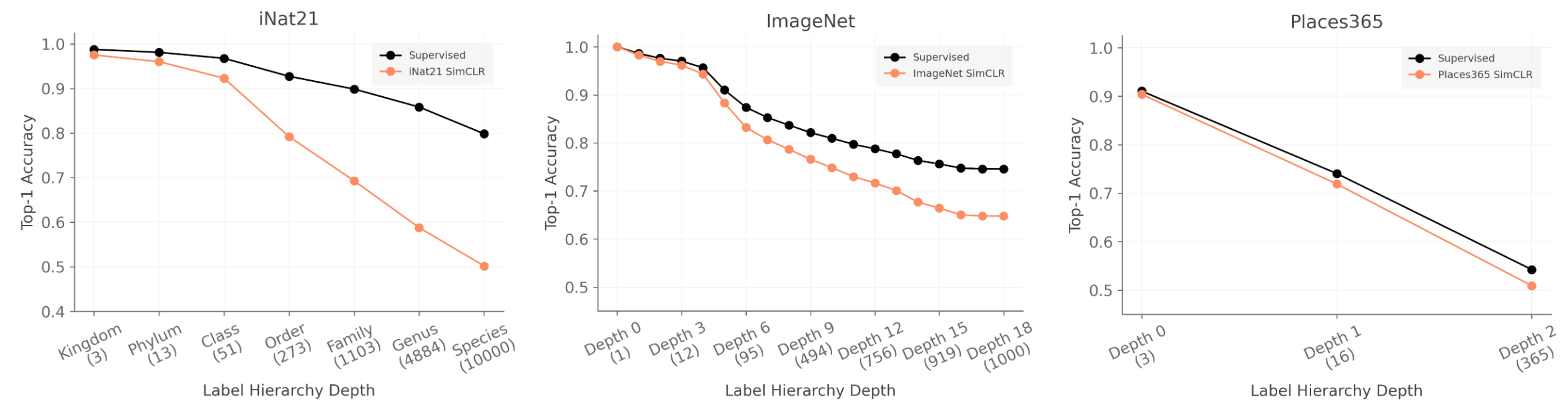
A relevant question for BioCLIP: does our species-level accuracy degrade as quickly? The authors also bring up the idea that contrastive learning might have a coarse-grained bias. I think this is very likely. I think that contrastive learning, based on its random sampling of negatives in the batch, is likely to sample examples that are dramatically different from the true positive, so the model doesn’t need to learn fine-grained instances. In a sense, after learning these coarser features, you want to choose examples that are very similar, then use those to force fine-grained representations.1 This would also be relevant in BioCLIP, where near the start of training, we could sample examples that have the same kingdom but different phylum, then at the end of training, sample examples that have the same kingdom, phylum, …, genus, but different species.
Zhang et al. 2022 (Use All The Labels: A Hierarchical Multi-Label Contrastive Learning Framework) propose a contrastive learning framework where the hierarchical distance between labels corresponds to the desired distance in the embedding space.
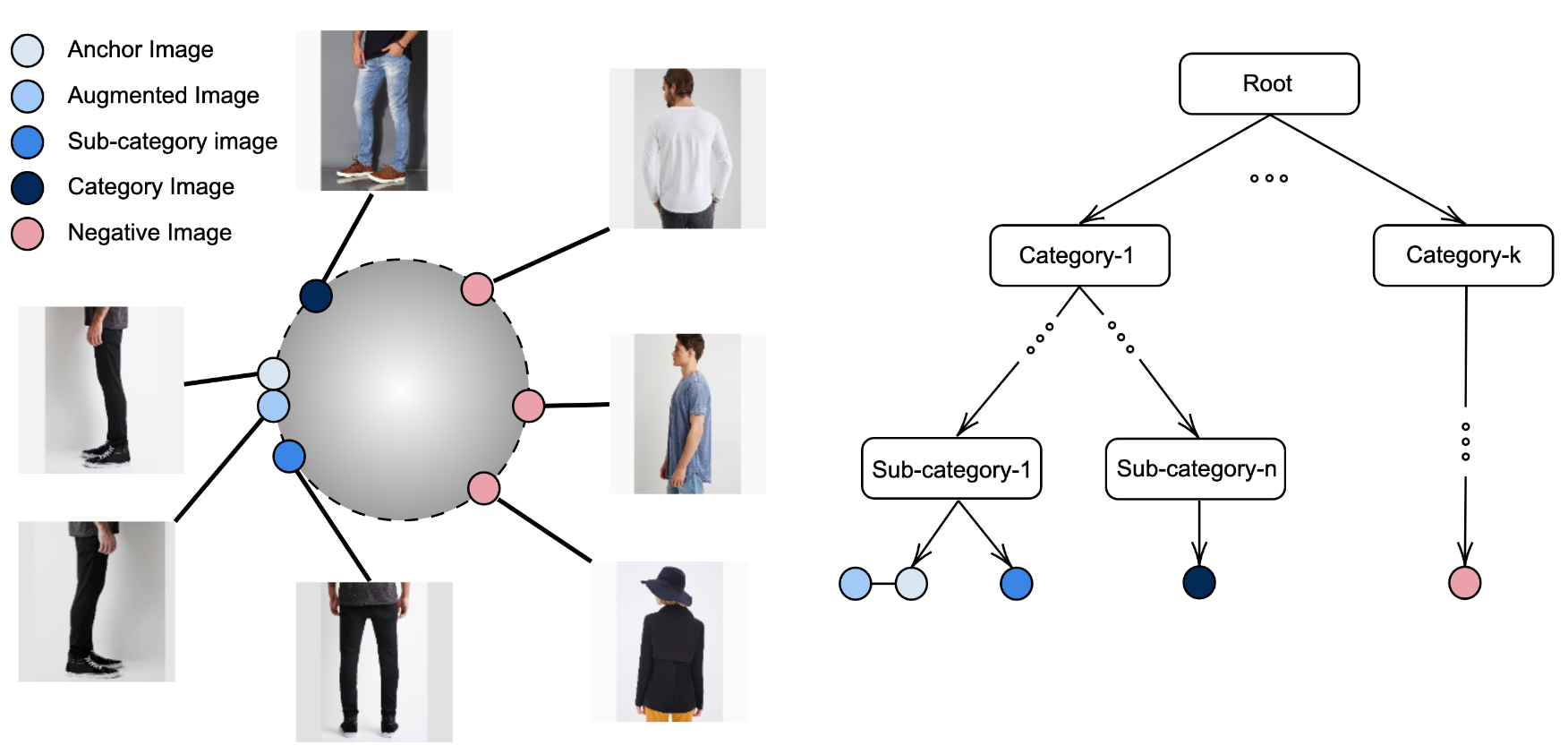
This actually outperforms cross entropy on both ImageNet and iNat17 in top-1 accuracy:
| ImageNet | iNat17 | |
|---|---|---|
| SimCLR | 69.53 | 54.02 |
| Cross Entropy | 77.6 | 56.8 |
| HiMulConE (Proposed) | 79.1 | 59.4 |
On the other hand, 56.8 top-1 accuracy on iNat17 is horrifically low. They use a ResNet-50 pretrained on ImageNet and only finetune the fourh layer’s parameters, which is a pretty weird choice.
Reading List
- Garnot and Landrieu 2021 (Leveraging Class Hierarchies with Metric-Guided Prototype Learning)
Sam Stevens, 2024