Learning Vision Representations from Language
This page is a literature review, mostly for my own purposes, of how to train vision models using language supervision, like OpenAI’s CLIP model. I update this page as I have time and energy to read and write about new papers. If you feel that your work should be mentioned here, please email me.
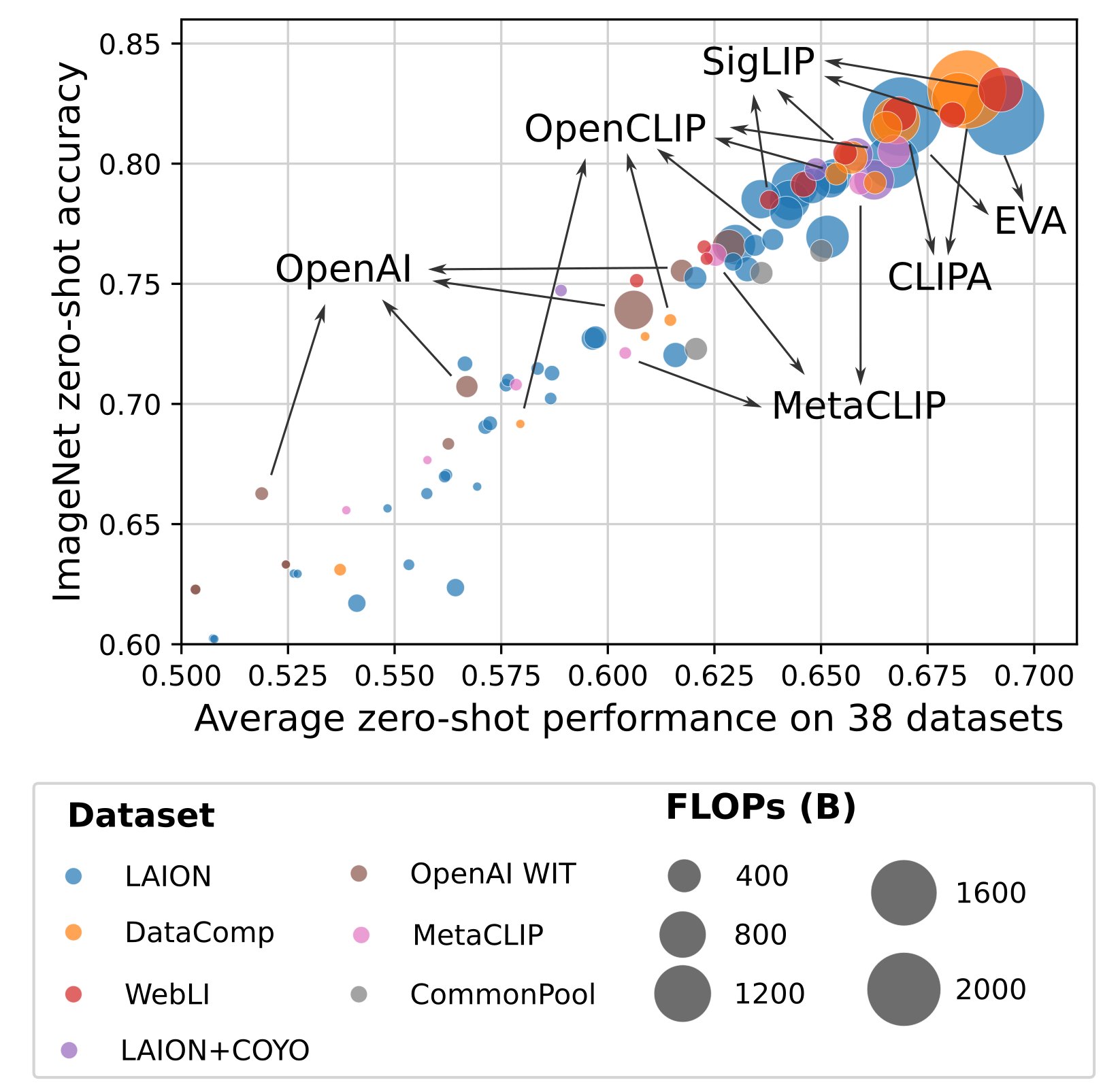
Table of Contents
- Foundational Works
- Data
- Issues
- Architecture
- Training
- Fine-Tuning
- Domain-Specific Models
- Contrastive vs. Captioning
- Further Reading
Foundational Works
- Learning Transferable Visual Models From Natural Language Supervision (CLIP)
- Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision (ALIGN)* Combined Scaling for Zero-shot Transfer Learning (BASIC)
Data
- DataComp: In search of the next generation of multimodal datasets
- OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
- [Redcaps: Web-curated image-text data created by the people, for the people]
- [WIT: wikipedia-based image text dataset for multimodal multilingual machine learning]
Li et al. 2023 (Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation, BLIP)
Pizzi et al. 2022 (A Self-Supervised Descriptor for Image Copy Detection, SSCD)
Xu et al. 2023 (CiT: Curation in Training for Effective Vision-Language Data) develop an online data curation loop that picks out image-text pairs that are most similar to the downstream classnames for whatever downstream task you want. They use pre-trained vision encoders, so the main goal is to better align text representations with the image representations. This doesn’t really help with the goal of learning better vision models from image-text data.
Xu et al. 2023 (Demystifying CLIP Data, MetaCLIP) develop a method for filtering web-scale data without using an existing CLIP model (like LAION). They exactly follow OpenAI’s CLIP procedure, which uses pure string matching. This outperforms LAION and OpenAI CLIP models across ImageNet 0-shot and a wide variety of downstream tasks. This is the first effort to exactly reproduce OpenAI’s WIT-400M without using existing CLIP models.
Multiple papers propose the use of hard negatives, where they add either additional images or additional texts to a batch that deliberately do not match any of the images or text in the batch. This is supposed to help with fine-grained reasoning. Some examples:
- FiGCLIP: Fine-Grained CLIP Adaptation via Densely Annotated Videos creates hard negative captions by replacing verbs in rule-based captions.
Issues
When and Why Vision-Language Models Behave Like Bags-of-Words, and What to Do About It? suggests that
- Note that (Image Captioners Are Scalable Vision Learners Too) shows that simply training a language model is enough to do well on ARO, so it might not be that useful.
Training
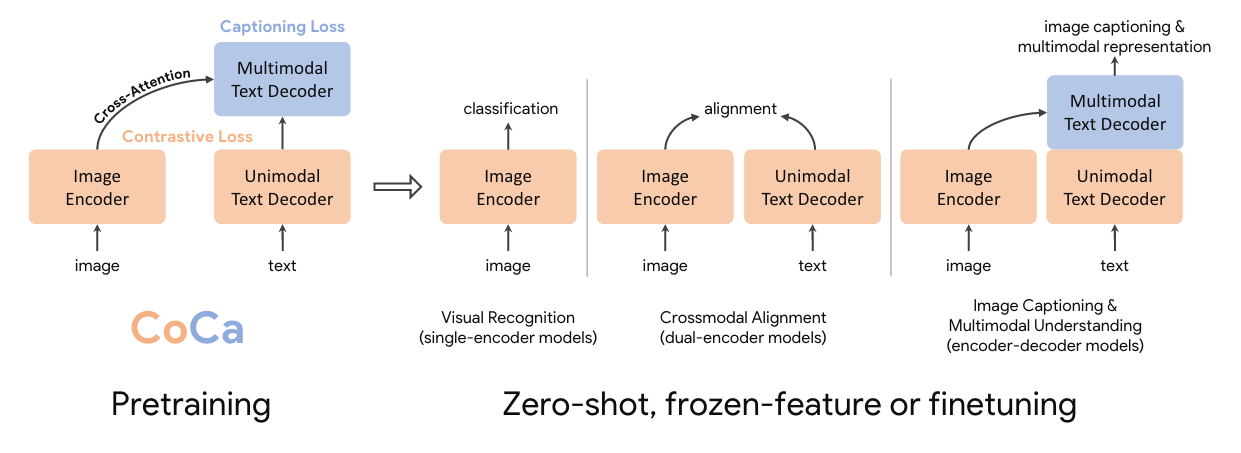
Yu et al. 2022 (CoCa: Contrastive Captioners are Image-Text Foundation Models) train a combination of unimodal vision and text transformers followed by a multimodal text decoder with a combination of contrastive loss between unimodal representations and a language modeling loss on the multimodal text decoder. See the screenshot below for details.
Tschannen et al. 2023 (Image Captioners Are Scalable Vision Learners Too) show that vision-encoder+ language-decoder transformer models that predict captions from images produce high-quality vision models. They add a parallel decoding trick, where the decoder must predict all caption tokens from just the image representations, similar to BERT predicting all language tokens instead of causal masking. They show that captioning is better than contrastive learning (1) when word order matters (ARO benchmark, see above) (2) in visual question answering (VQAv2 benchmark) and (3) on fine-grained classification tasks (improves on Flowers, Cars, Birds, Pets and Dogs). However, they note that the text decoder is fairly useless; their approach mostly leads to a strong vision model that should be used on its own.
Li et al. 2023 (Scaling Language-Image Pre-training via Masking, FLIP) propose dropping image patches from the input before the vision encoder sees them. This dramatically speeds up training because the sequence length is shorter (50% or even 25% of the original length) and doesn’t reduce encoder quality; it’s basically a free win.
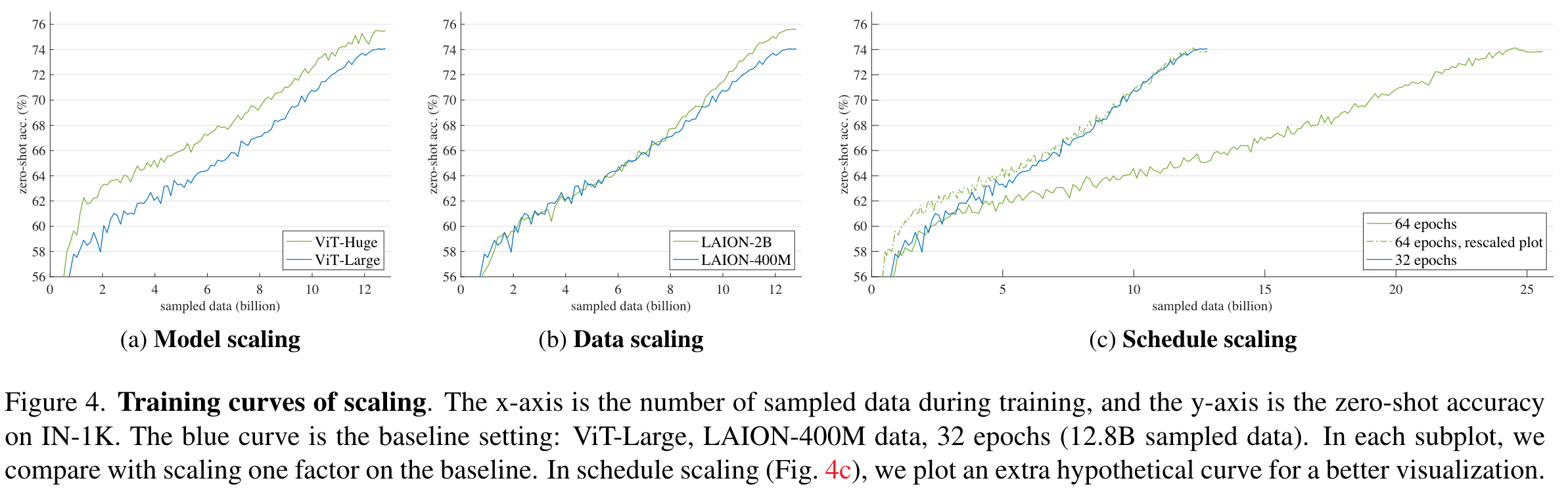
They explore data scaling by moving from LAION-400M to LAION-2B, but keeping the total number of samples seen during training the same. They find that “for the tasks studied here, data scaling is in general favored for zero-shot transfer, while model scaling is in general favored for transfer learning” (emphasis mine). See the screenshot below for more details.
Sun et al. 2023 (EVA-CLIP: Improved Training Techniques for CLIP at Scale)
Fine-Tuning
Lewis et al. 2023 (Generating Image-Specific Text for Fine-grained Object Classification, GIST) use domain-specific prompts with GPT-4 to generate fine-grained class-level descriptions. They then match the descriptions with images using CLIP to a small subset of the class-level descriptions. Finally, they use GPT-4 to summarize the now image-level descriptions. Finally, they fine-tune CLIP models on the new image, text dataset. This method produces fine-grained image-level texts for arbitrary labeled datasets.
Domain-Specific Models
Christensen et al. 2023 (Multimodal Foundation Models For Echocardiogram Interpretation, EchoCLIP) train a CLIP model on 1M cardiac ultrasound videos and the expert interpretations from 224K studies across nearly 100K patients. EchoCLIP uses a ConvNeXt image encoder. The authors use EchoCLIP to measure the similarity between two echocardiograms and classify whether two echocardiograms are from the same patient (challenging for human physicians). They use a regular-expression-based tokenizer to enable more efficient tokenizing, reducing the average number of text tokens from 530.3 to only 63.8.
Zhang et al. 2023 (Large-Scale Domain-Specific Pretraining for Biomedical Vision-Language Processing, BiomedCLIP) train a CLIP model on 15M figure-caption pairs gathered from PubMed Central articles. The authors improve upon the base CLIP architecture with a domain-specific pre-trained text encoder (PubMedBert, Gu et al. 2021), a longer context (256 tokens instead of 77) and larger images with patch dropout (448x488, 50% patch dropout until the last epoch) leads to 2 points improvement on txt2img and img2txt recall@1.
Some interesting decisions and findings:
- They re-initialize the vision transformer rather than start with a pre-trained ViT-B/16 model (Table 6)
- 224x224 pretraining does better than 448x448 on 4/5 zero-shot classification tasks. There’s a significant drop in accuracy for the two LC2500 tasks: 72.17 to 47.96 and 94.65 to 70.66.
Lu et al. 2023 (Towards a Visual-Language Foundation Model for Computational Pathology, CONCH) train on 1.17M image-caption pairs from educational sources and PubMed’s Open Access dataset. They tuned and used an object detection model, a language model and an image-text matching model to gather 1.79M pairs which were then filtered to 1.17M to create the CONCH dataset. They perform unimodal self-supervised pre-training on large-scale domain-specific unimodal data, then do multimodal pretraining on their CONCH dataset.1
CONCH-trained models do better than PLIP, BiomedCLIP and OpenAI’s CLIP.
Contrastive vs. Captioning
An interesting split has emerged in learning vision models from language: should you use a contrastive objective, where the fundamental goal is image-text matching, or a captioning objective, where the fundamental goal is generating the text for a given image? Both appear to be quite scalable and lead to strong results. What are the tradeoffs?
- A Study of Autoregressive Decoders for Multi-Tasking in Computer Vision
- LocCa: Visual Pretraining with Location-aware Captioners
- Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
- Image Captioners Are Scalable Vision Learners Too
- CoCa: Contrastive Captioners are Image-Text Foundation Models
Further Reading
- MiniVLM: A Smaller and Faster Vision-Language Model was pre-CLIP, so I haven’t read it yet.
- GIT: A Generative Image-to-text Transformer for Vision and Language
- [Reproducible scaling laws for contrastive language-image learning]
- [CLIPPO: Image-and-language understanding from pixels only]
- [Language in a bottle: Language model guided concept bottlenecks for interpretable image classification]
- [Prompt, generate, then cache: Cascade of foundation models makes strong few-shot learners]
- [Finetune like you pretrain: Improved finetuning of zero-shot vision models]
- [Sus-x: Training-free name-only transfer of vision-language models]
- [Multimodality helps unimodality: Cross-modal few-shot learning with multimodal models]
- [Enhancing CLIP with GPT-4: Harnessing Visual Descriptions as Prompts]
- Grounded Language-Image Pre-training
- Ikezogwo et al. 2023 (Quilt-1M: One Million Image-Text Pairs for Histopathology, QUILT)
Appendix: Vision Inputs for Language Models
Recently vision-language model has implied that you have a language model that incorporates vision inputs, like GPT-4 or Flamingo. I’m more interested in training high-quality vision models through image-caption supervision. Other noteworthy works on this topic:
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- Qwen-VL: A Frontier Large Vision-Language Model with Versatile Abilities
They train a 24-layer GPT-style causal language model, then use the first 12 layers for their unimodal text encoder and the last 12 layers for their multimodal decoder. They cite Lu et al. 2023 for this idea.↩︎
Sam Stevens, 2024